
SEO Webinars & Hands-on Training

One of the most important aspects of having a strong SEO strategy is to understand how your potential customers search the web. When you can understand what your target market wants, you can effectively reach and engage with these users.

Learn How To Increase Your SEO Keyword Relevance, Authority, And Search Engine Ranking

Search engines are designed to provide the most relevant and popular search results for a search query! Search results are ranked by the popularity and quality of the web page, and how useful and relevant it is to the user’s query.

Search engines are answer providers. When you enter a query into a search box, search engines provide information by looking through billions of pages that have been stored on its servers. A search engine’s goal is to provide the most relevant and popular information for each query. Results are ranked by the popularity and quality of the website as well as how useful and relevant they are for the user’s query.
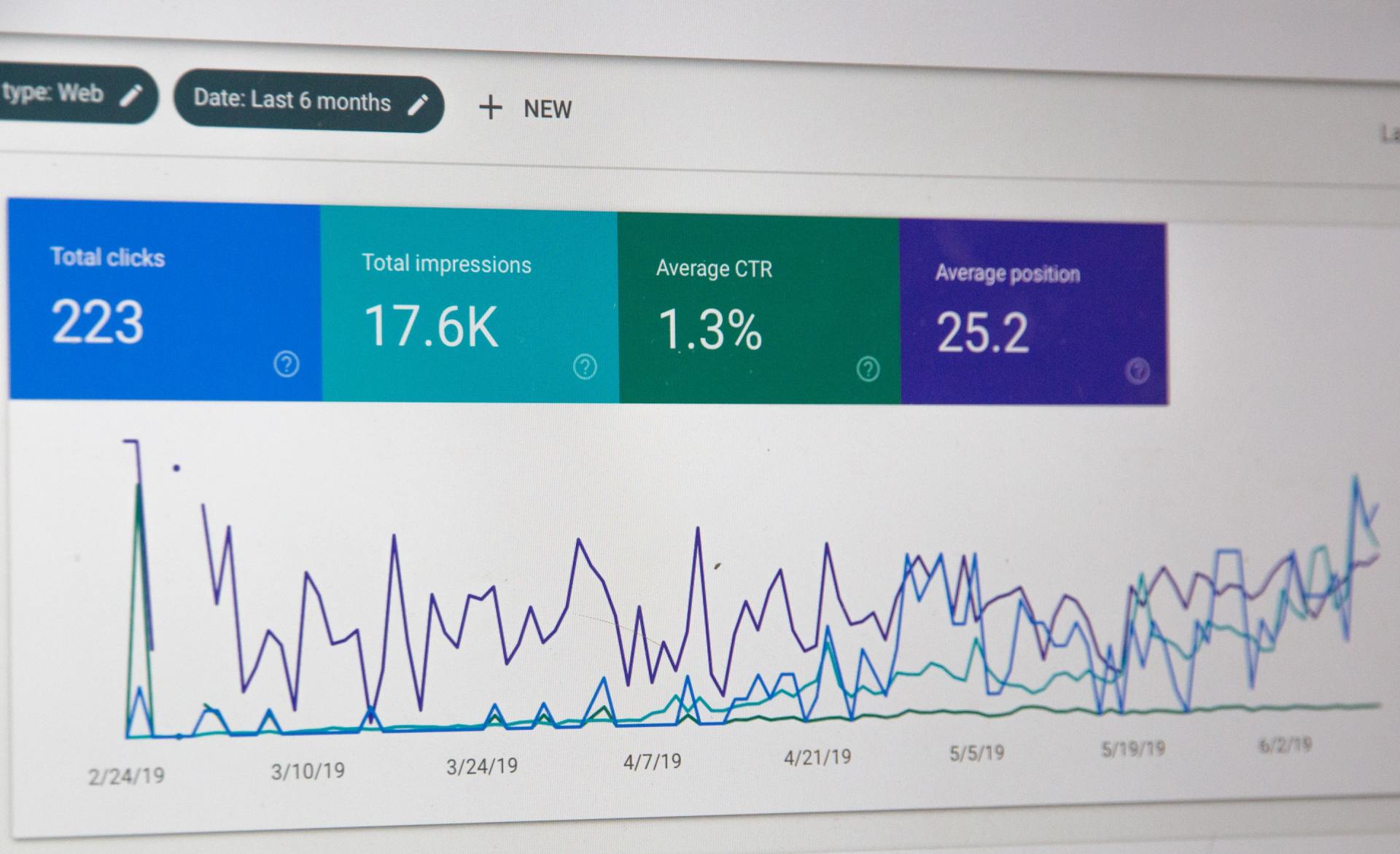
Well executed SEO can be the difference between getting 100,000 visitors a day and 500 per month. The higher your website is on the first page of Google the more traffic your website has access to.

Ethical SEO professionals should never guarantee future results with position or length of time. When these types of promises are made, they are most likely not playing by the rules and using spamming or cloaking which can lead to huge search engine penalties.

Time flies and evolution happens. Changes are implemented every day, be it a simple system update or a large-scale improvement that is seen by everyone.
3 out of 4 searchers don't go past the first page of Google because we believe that if a vendor is not on the first page he's not good enough!

Don’t miss this advanced SEO training, tactics and tools, prepared by Green Lotus Founder Bassem Ghali! It’s never easy to preform keyword research and understand all the relevant metrics. During this webinar you will learn the 3 steps and tools to help select the most effective keywords for your products, services, and website content.
